


THE REINFORCEMENT
LEARNING REVOLUTION
Moving from simple pattern recognition to high-stakes autonomous decision-making.
RL has transitioned from game-playing to a foundational pillar of modern Artificial General Intelligence(AGI). Its ability to solve sequential problems makes it fundamentally distinct from Supervised Learning.










Modern RL Algorithms
The PEBBLE (Unsupervised Pre-training and preference-Based learning via relaBeLing Experience) algorithm achieves state-of-the-art performance in preference-based reinforcement learning by extending the Soft Actor-Critic (SAC) framework with unsupervised pre-training and a novel experience-relabeling mechanism.
SAC itself is a highly sample-efficient, off-policy algorithm that uses entropy maximization to balance exploration and exploitation, making it ideal for the complex robotic manipulation tasks where PEBBLE excels. While SAC offers superior data efficiency, it is often compared to Proximal Policy Optimization (PPO), an on-policy algorithm that is less sample-efficient but significantly more stable and easier to tune for large-scale applications.
This robustness is precisely why PPO was chosen for InstructGPT, where it powers the Reinforcement Learning from Human Feedback (RLHF) phase to align language model outputs with human preferences without the training instabilities common in off-policy methods. By bridging these techniques, researchers can choose between SAC’s efficiency for physical control or PPO’s reliability for complex alignment in generative AI.
RL-SaLLM-F (Reinforcement Learning with Self-augmented Large Language Model Feedback) extends the PEBBLE framework by replacing the need for scripted teachers or real-time human feedback with a self-sustaining loop where an LLM acts as an autonomous preference provider.
Meta-World: General Purpose Robotic Intelligence
Meta-World serves as a "Decathlon for robotics," offering 50 diverse manipulation tasks that provide a standardized benchmark for evaluating multi-task and meta-reinforcement learning algorithms.
It moves the field beyond narrow, single-skill agents by measuring an agent's ability to generalize to new objectives and adapt with minimal data, which is a critical requirement for achieving true autonomy.
Ultimately, the authors aim to provide a foundational platform that accelerates the development of general-purpose robotic intelligence capable of mastering a wide variety of human-centric manipulation skills in complex environments.
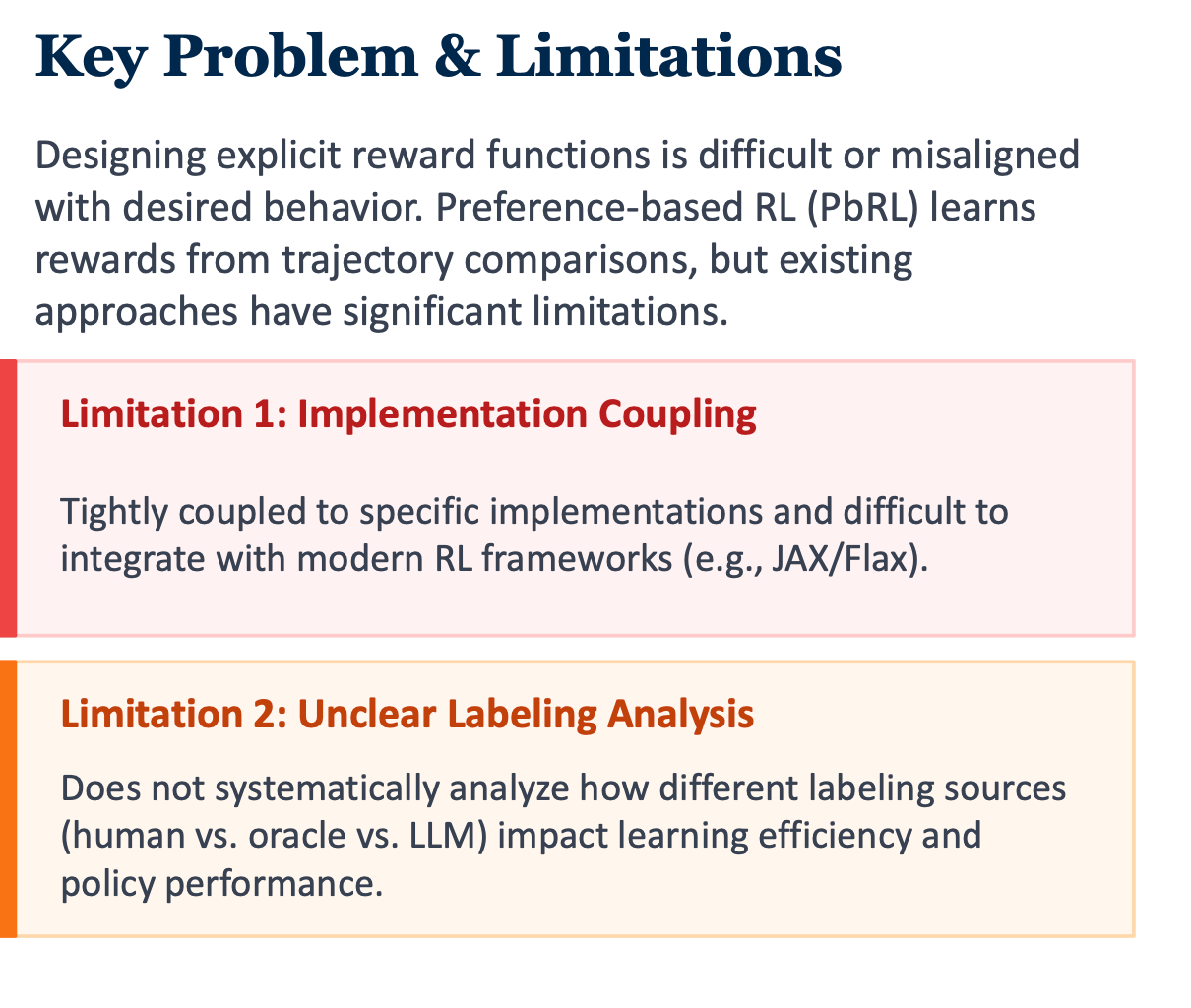
The Challenge: Learning from Preferences in
Real-World Tasks



Our Solution: Unified RL-SaLLM-F Pipeline with Labeling Variants - SaLLMF v2


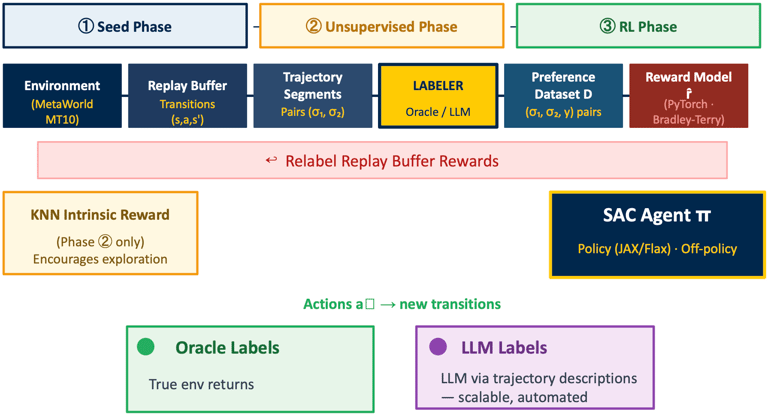
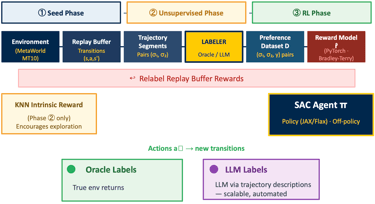
Method Overview
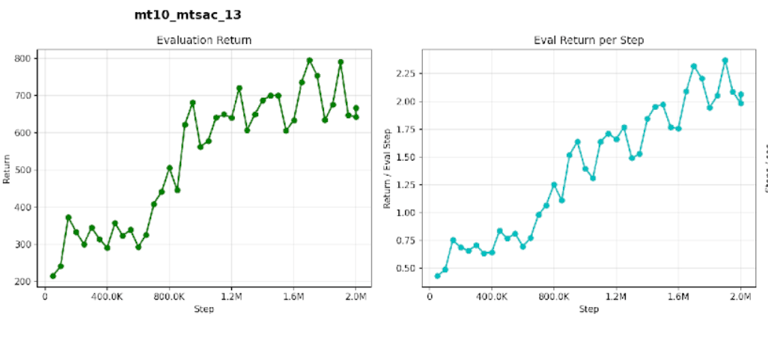
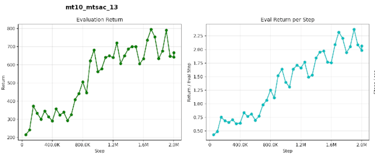
We compare a vanilla MTSAC baseline against SaLLMF v2 variants.
SaLLMF v2 uses a three-stage schedule: seed, unsupervised exploration, then RL with reward learning.
Variants differ by feedback source: environment reward, oracle preference labels, or LLM preference labels.
Additional ablations vary feedback budget, pacing schedule, and trajectory augmentation.
This lets us separate scheduling effects from reward-learning effects.
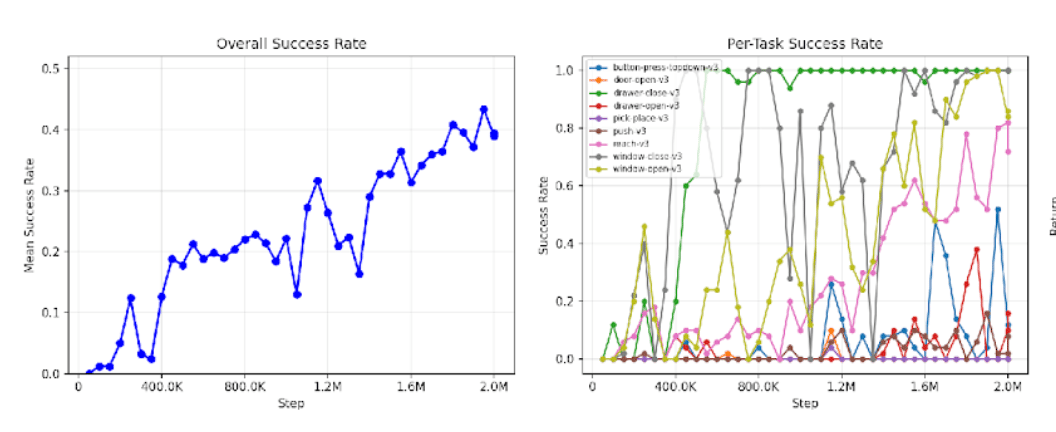
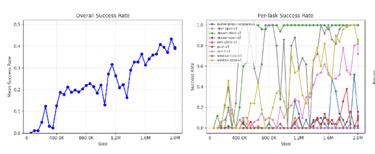
Baseline Control Results
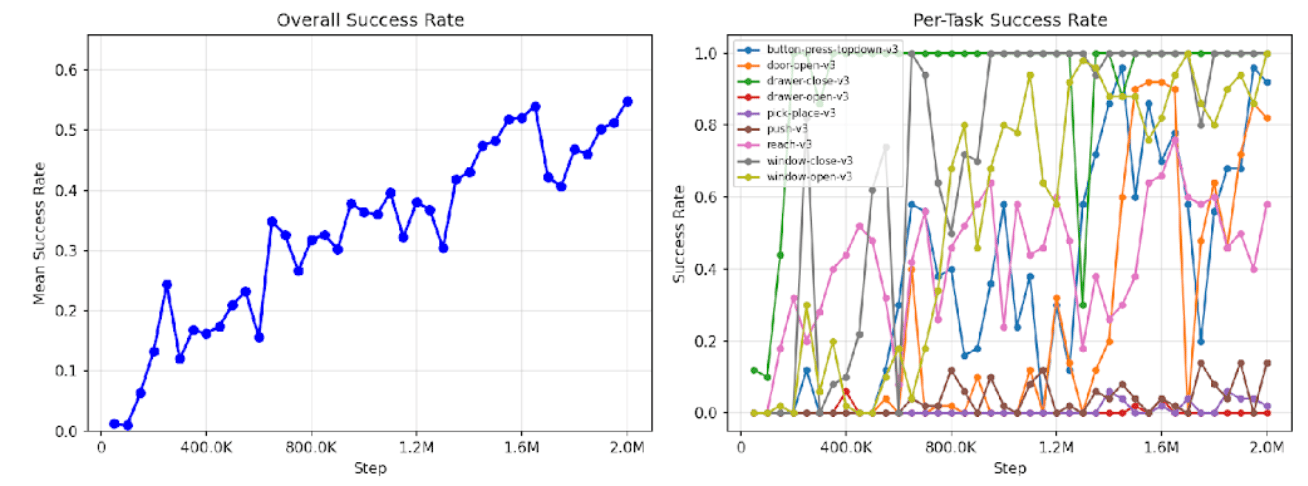
Vanilla MTSAC final success: 39.4%
Vanilla MTSAC peak success: 43.4%
It first reaches 30% success at 1.15M steps
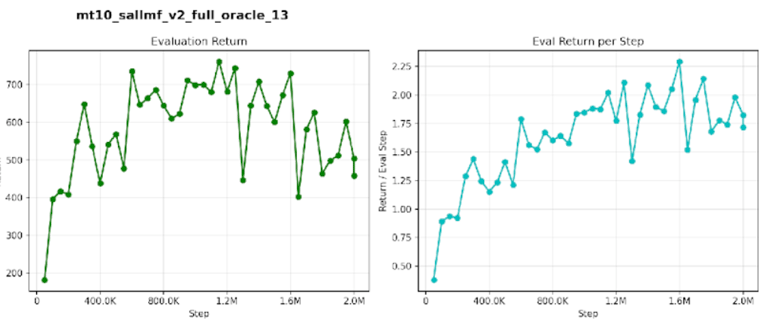
SaLLMF v2 full-oracle final success: 53.0%
SaLLMF v2 full-oracle peak success: 53.2%
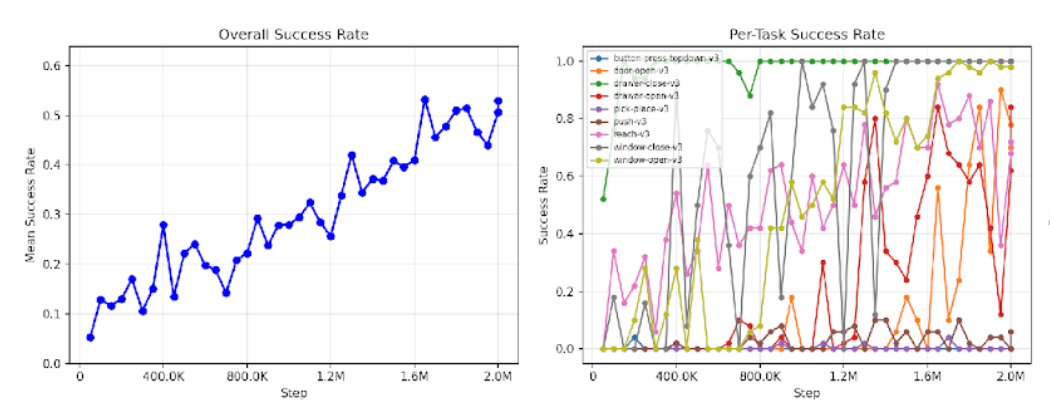
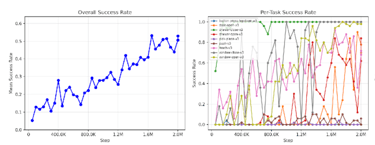
Why the Full Oracle Control Matters -
The full-oracle incorporates ONLY the unsupervised learning step of SaLLMF v2.
It uses the SaLLMF v2 stage structure and training schedule without a reward model.
It reaches 50% success at 1.65M steps.
This makes it a strong control, not just a renamed baseline.
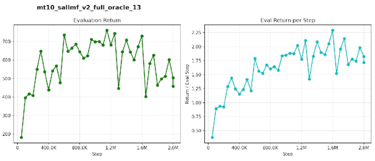
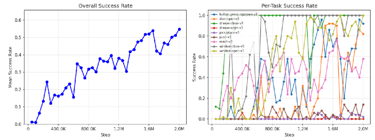
LLM Feedback - Main Result
Default LLM-label run final success: 55.6%
Default LLM-label run peak success: 55.6%
This is competitive with the strong full-oracle control.
Larger-budget LLM run final success: 58.0%
Larger-budget LLM run peak success: 58.4%
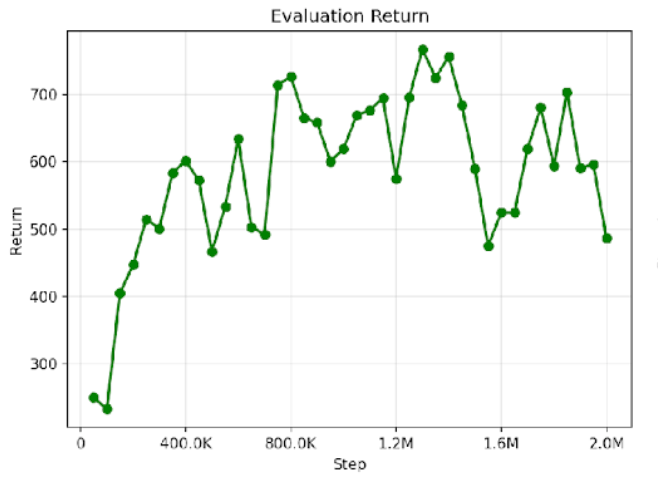
Conclusion
SaLLMF v2’s training schedule is materially stronger than plain MTSAC on MT10.
LLM feedback is competitive with strong controls and improves with larger feedback budget.
We found through ablations that early reward model labeling consistently produces better results.
Reward-model accuracy alone is not a reliable proxy for downstream control quality.
Some tasks remain consistently hard, highlighting persistent task heterogeneity.
S. Tu, J. Lin, Q. Zhang, X. Tian, L. Li, X. Lan, and D. Zhao, "Online Preference-based Reinforcement Learning with Self-augmented Feedback from Large Language Model," in Proc. 24th Int. Conf. Autonomous Agents and Multi-Agent Systems (AAMAS), Detroit, MI, USA, 2025.
K. Lee, L. Smith, and P. Abbeel, "PEBBLE: Feedback-Efficient Interactive Reinforcement Learning via Relabeling Experience and Unsupervised Pre-training," in Proc. 38th Int. Conf. Mach. Learn. (ICML), vol. 139, Jul. 2021, pp. 6152–6163.
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, "Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor," in Proc. 35th Int. Conf. Mach. Learn. (ICML), vol. 80, Jul. 2018, pp. 1861–1870.
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, "Proximal Policy Optimization Algorithms," arXiv preprint arXiv:1707.06347, Aug. 2017.
L. Ouyang et al., "Training language models to follow instructions with human feedback," in Advances in Neural Information Processing Systems (NeurIPS), vol. 35, Dec. 2022, pp. 27730–27744.
Chai, Y., Sun, H., Fang, H., Wang, S., Sun, Y., & Wu, H. (2024). MA-RLHF: Reinforcement learning from human feedback with macro actions. arXiv. https://doi.org/10.48550/arxiv.2410.02743
Doya, K. (2007). Reinforcement learning: Computational theory and biological mechanisms. HFSP Journal, 1(1), 30. https://doi.org/10.2976/1.2732246
Liu, S., Fang, W., Hu, Z., Zhang, J., Zhou, Y., Zhang, K., Tu, R., Lin, T., Huang, F., Song, M., Li, Y., & Tao, D. (2025). A survey of direct preference optimization. arXiv. https://doi.org/10.48550/arxiv.2503.11701 Cited by: 39
Ouyang, Long, et al. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems.
Ponte, E. (2026). Reinforcement learning: A paradigm shift in AI training and its competitive implications. Journal of Business & Technology Law, 21(1).
Yue, Y., Chen, Z., Lu, R., Zhao, A., Wang, Z., Yue, Y., Song, S., & Huang, G. (2025). Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? NeurIPS 2025 Oral. https://doi.org/10.48550/arxiv.2504.13837
DeepSeek-AI, "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning," Technical Report, Jan. 2025. [Online]. Available: https://github.com/deepseek-ai/DeepSeek-R