


Research on RAGs
The following section describes research work I completed during my Masters in AI at the University of Michigan, department of Computer Science in 2025.
For this project, I focussed on Retrieval Augmented Generation (RAG), a mechanism to provide context to an LLM(Large Language Model) that is relevant to the subject matter being queried. Specifically the purpose was to investigate how effectively the LLM could answer questions based on a complex knowledge graph of documents.
LLMs have a wide range of applications
The use of Large language models(LLMs) have been one of the most successful and influential areas in Artificial Intelligence lately.
Today people throughout the world are using interfaces built on top of LLMs to aid in a variety of tasks as well help in human comprehension and understanding.
Some top areas of usage according to Forbes are:
Assisting With Clinical Diagnoses
Mapping Cybersecurity Regulations To Policies And Controls
Expediting Claims Processing
Tracking And Analyzing Customer Feedback






Correctness is a concern
However, correctness of the results given by LLMs and avoiding hallucinations are still a significant concern.
Four major correctness related drawbacks to using LLMs are:
Limitations of Reasoning
Limitations of Knowledge or Expertise
Limitations of Understanding
Limitations of Planning and Execution


Dataset and Goals
My goal was to develop an intuition around the advantages and disadvantages of Vector RAG vs Graph RAG based on analysis in a complex Question and Answer Dataset
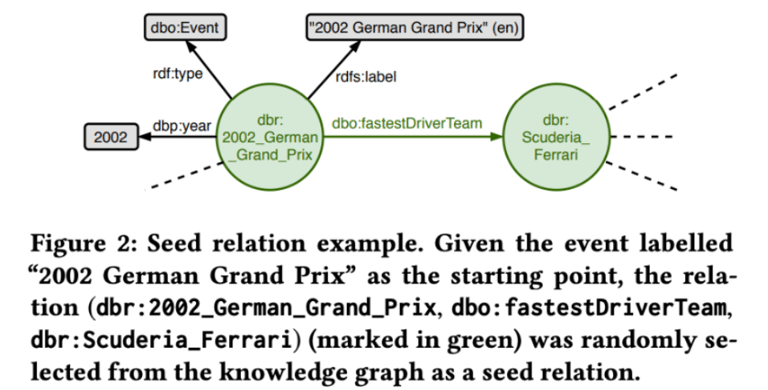
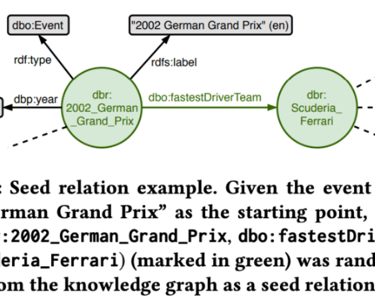
Created on top of a Knowledge Graph of Documents
To achieve this goal, they approach the query generation via a random walk through the knowledge graph, starting from randomly selected relations.
The curating of the dataset including labeling of the answer is done manually by the authors based on the selected nodes.
The Event QA Dataset
This Question and Answer Dataset was created and published as part of a research paper
This dataset provides over 1000 complex, manually curated, event-centric questions over the DBPedia knowledge graphs (built on Wikipedia).
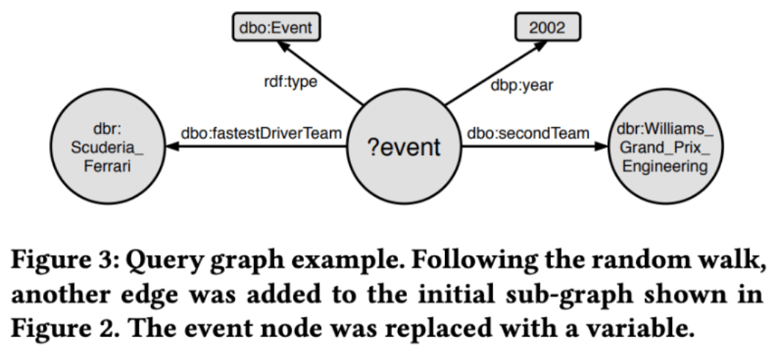
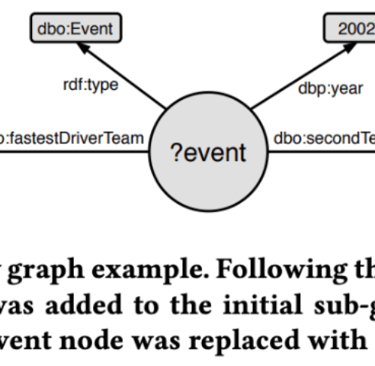
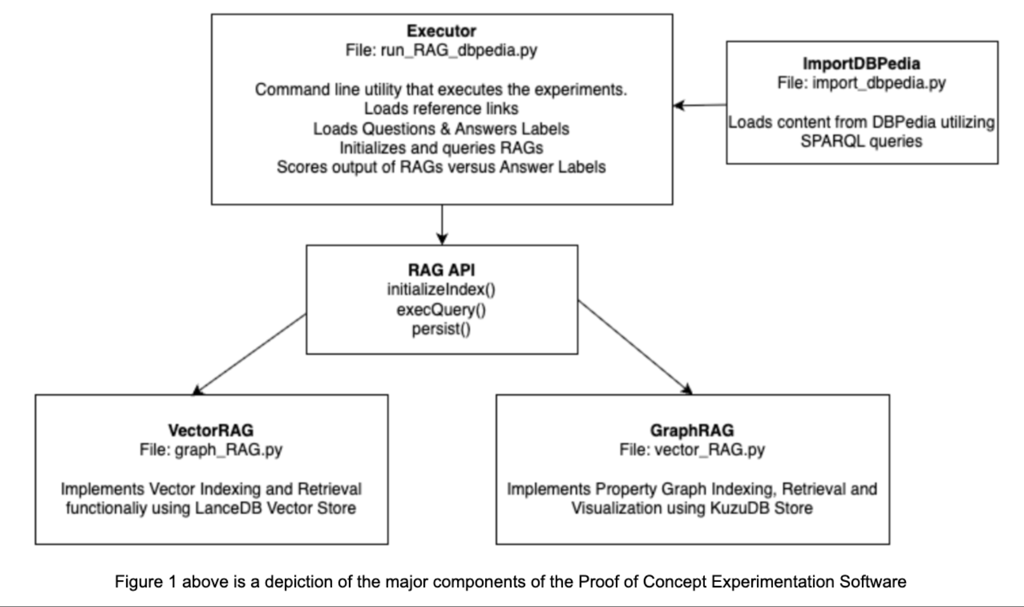
RAG Pipeline Overview
As part of this project, I developed a RAG pipeline that can be used in either Graph or Vector mode. The key steps are outlined below. The OpenAI 4o mini LLM was used for the experiments in both Vector and Graph implementations.
Model Tuning
I tuned both models to maximize their performance during the traing phase of the experiment
Vector RAG - tuned the top-k parameter, which returns the most relevant k results (Tried k=4 and 10)
The Vector DB utilized the cosine similarity algorithm - this measures the relevance of document chunks versus the query.
Graph RAG - I completed extensive schema tuning related to the questions and domain space:
Tailored entities and relations that applied well for all questiond in the training set.


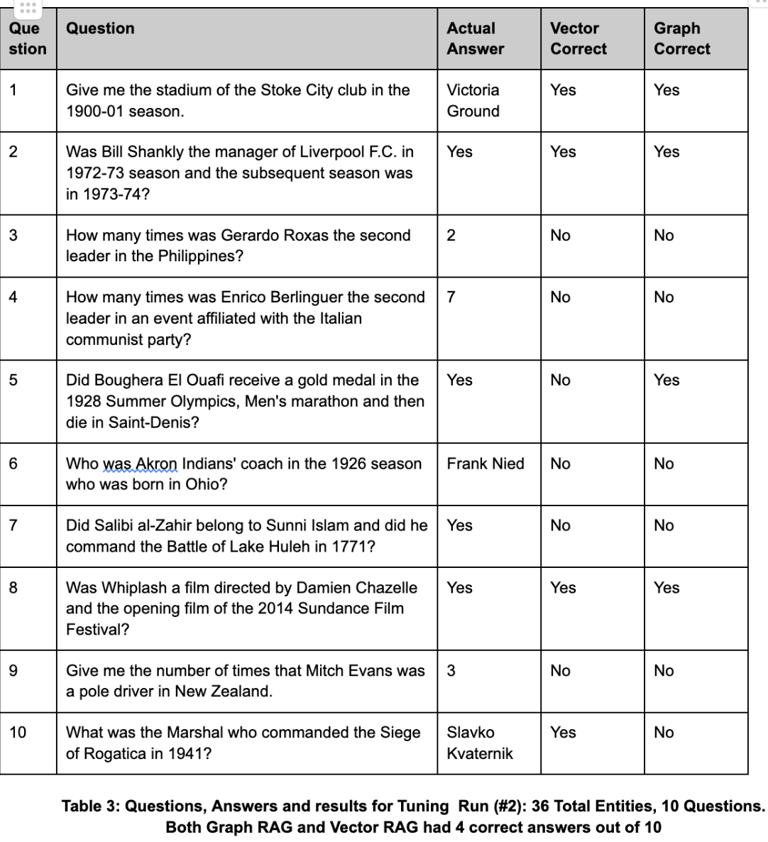
Example Results
The table on the left is a sampling of the questions that were asked and whether the response was correct for the Vector and Graph RAG
Conclusions
Strengths in Graph RAG
Capable of understanding deep relationships.
More configurable and tunable to enable the understanding of complex relationships.
Better suited for a single well understood domain rather than a very general expansive area


Strengths in Vector RAG
More performant, requiring less compute and memory resources
Performs better with minimal tuning and configuration needed.
More adaptable to different datasets out of the box


Further Exploration
Experiment with prompt tuning on the Graph RAG - LLM Prompts are used in conjunction with the Graph Schema during the indexing phase to capture the entities and relationships
Applying the Graph RAG to a well defined problem space rather than a broad area - the current question and answer dataset was broad in nature.
Vector RAG LLM prompt tuning can help in the understanding layer and final translation of returned chunks to the summarized result provided by the LLM.


References
Bhaskarjit Sarmah, Benika Hall, Rohan Rao, Sunil Patel, Stefano Pasquali, Dhagash Mehta.
HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction arXiv:2408.04948v1 2024
Ali Ismayilov1, Dimitris Kontokostas2, S¨oren Auer, Jens Lehmann, Sebastian Hellmann. Wikidata through the Eyes of DBpedia arXiv:1507.04180 2015
Tarcísio Souza Costa, Simon Gottschalk, Elena Demidova. Event-QA: A Dataset for Event-Centric Question Answering over Knowledge Graphs arXiv:2004.11861v2 2020
Successful-real-world-use-cases-for-llms-and-lessons-they-teach
MIT Sloan Management Review - LLM Limitations