
When Do Tools and Planning Help Large Language Models Think?
A Cost- and Latency-Aware Benchmark
Published IEEE, March 2026 Arxiv
Modern large language models (LLMs) increasingly rely on inference-time planning and external tools to improve reasoning. We benchmark this behavior on two real-world settings: event-centric question answering over graph-structured knowledge (Event-QA) and persuasive response generation in Reddit ChangeMyView (CMV). Using LangChain and LangGraph, we compare a one-shot baseline against a plan–execute–replan agent equipped with task-specific tools (DBpedia SPARQL Protocol and RDF Query Language (SPARQL)/lookup/schema exploration, Wikipedia-focused retrieval, and topical web search).
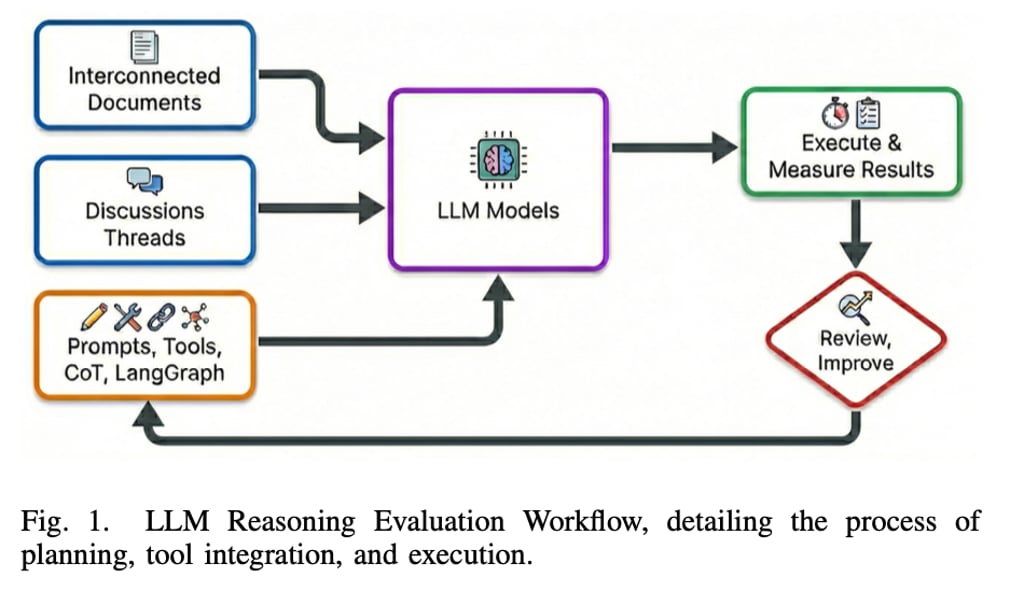
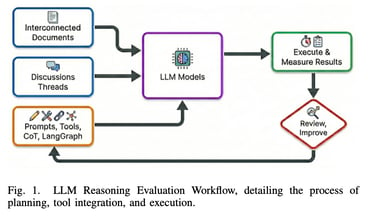








References
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones,A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” arXiv preprint arXiv:1706.03762, 2017. [Online]. Available: https://arxiv.org/abs/1706.03762
Z. Wang, Z. Chu, T. V. Doan, S. Ni, M. Yang, and W. Zhang, “History, development, and principles of large language models—an introductory survey,” arXiv preprint arXiv:2402.06853, 2024. [Online]. Available: https://arxiv.org/abs/2402.06853
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” arXiv preprint arXiv:2201.11903, 2022. [Online]. Available: https://arxiv.org/abs/2201.11903
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” arXiv preprint arXiv:2203.11171, 2022. [Online]. Available: https://arxiv.org/abs/2203.11171
C. Snell, J. Lee, K. Xu, and A. Kumar, “Scaling LLM test-time compute optimally can be more effective than scaling model parameters,” arXiv preprint arXiv:2408.03314, 2024. [Online]. Available: https://arxiv.org/abs/2408.03314
N. Muennighoff, Z. Yang, W. Shi, X. L. Li, F. Li, H. Hajishirzi, L. Zettlemoyer, P. Liang, E. Candes, and T. Hashimoto, “s1: Simple test-time scaling,” arXiv preprint arXiv:2501.19393, 2025. [Online]. Available: https://arxiv.org/abs/2501.19393
S. Yao, D. Yu, J. Zhao, I. Shafran, T. L. Griffiths, Y. Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,” arXiv preprint arXiv:2305.10601, 2023.[Online]. Available: https://arxiv.org/abs/2305.10601
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. K¨ uttler, M. Lewis, W. Yih, T. Rockt¨ aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Advances in Neural Information Processing Systems, vol. 33. Curran Associates, Inc., 2020, pp. 9459–9474. [Online]. Available: https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao, “React: Synergizing reasoning and acting in language models,” arXiv preprint arXiv:2210.03629, 2022. [Online]. Available: https://arxiv.org/abs/2210.03629
T. Schick, J. Dwivedi-Yu, R. Dess` ı, R. Raileanu, M. Lomeli, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” arXiv preprint arXiv:2302.04761, 2023. [Online]. Available: https://arxiv.org/abs/2302.04761
L. Gao, A. Madaan, S. Zhou, U. Alon, P. Liu, Y. Yang, J. Callan, and G. Neubig, “PAL: Program-aided language models,” arXiv preprint arXiv:2211.10435, 2022. [Online]. Available: https: //arxiv.org/abs/2211.10435
W. Chen, X. Ma, X. Wang, and W. W. Cohen, “Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks,” arXiv preprint arXiv:2211.12588, 2022. [Online]. Available: https://arxiv.org/abs/2211.12588
T. S. Costa, S. Gottschalk, and E. Demidova, “Event-qa: A dataset for event-centric question answering over knowledge graphs,” in Proceedings of the 29th ACM International Conference on Information & Knowledge Management (CIKM), 2020, pp. 3157–3164. [Online]. Available: https://arxiv.org/abs/2004.11861
C. Tan, V. Niculae, C. Danescu-Niculescu-Mizil, and L. Lee, “Winning arguments: Interaction dynamics and persuasion strategies in good-faith online discussions,” in Proceedings of the 25th International Conference on World Wide Web (WWW), 2016, pp. 613–624. [Online]. Available: https://arxiv.org/abs/1602.01103
J. Lehmann, R. Isele, M. Jakob, A. Jentzsch, D. Kontokostas, P. N. Mendes, S. Hellmann, M. Morsey, P. van Kleef, S. Auer, and C. Bizer, “DBpedia—a large-scale, multilingual knowledge base extracted from wikipedia,” Semantic Web, vol. 6, no. 2, pp. 167–195, 2015.
S. Raschka, “The state of LLM reasoning model inference: Inference-time compute scaling methods to improve reasoning models,” https://magazine.sebastianraschka.com/p/state-of-llm-reasoning-and-inference-scaling, Mar. 2025, ahead of AI.
DeepSeek-AI, D. Guo, D. Yang, H. Zhang, J. Song et al., “Deepseek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning,” arXiv preprint arXiv:2501.12948, 2025. [Online]. Available: https://arxiv.org/abs/2501.12948
Y. Li, X. Hu, X. Qu, L. Li, and Y. Cheng, “Test-time preference optimization: On-the-fly alignment via iterative textual feedback,” arXiv preprint arXiv:2501.12895, 2025. [Online]. Available: https://arxiv.org/abs/2501.12895
Y. Wang, Q. Liu, J. Xu, T. Liang, X. Chen, Z. He, L. Song, D. Yu, J. Li, Z. Zhang, R. Wang, Z. Tu, H. Mi, and D. Yu, “Thoughts are all over the place: On the underthinking of o1-like LLMs,” arXiv preprint arXiv:2501.18585, 2025. [Online]. Available: https://arxiv.org/abs/2501.18585
J. Pan, S. Deng, and S. Huang, “Coat: Chain-of-associated-thoughts framework for enhancing large language models reasoning,” arXiv preprint arXiv:2502.02390, 2025. [Online]. Available: https://arxiv.org/abs/2502.02390
LangChain, “Langchain overview,” https://docs.langchain.com/oss/python/langchain/overview, accessed: 2025-12-29.
“Langgraph overview,” https://docs.langchain.com/oss/python/langgraph/overview, accessed: 2025-12-29.
“Graph api overview (langgraph),” https://docs.langchain.com/oss/python/langgraph/graph-api, accessed: 2025-12-29.
DBpedia Association, “Sparql over online databases (dbpedia public endpoint documentation),” https://www.dbpedia.org/resources/sparql/, accessed: 2025-12-29.
W3C SPARQL Working Group, “SPARQL 1.1 query language,” https://www.w3.org/TR/sparql11-query/, 2013, w3C Recommendation. Accessed: 2025-12-29.
Tavily, “Tavily search api: Search endpoint,” https://docs.tavily.com/documentation/api-reference/endpoint/search, accessed: 2025-12-29.
OpenAI, “Gpt-4o model (openai api documentation),” https://platform.openai.com/docs/models/gpt-4o, accessed: 2025-12-29.
“Gpt-4o mini model (openai api documentation),” https://platform.openai.com/docs/models/gpt-4o-mini, accessed: 2025-12-29.
“Pricing — openai api,” https://platform.openai.com/docs/pricing, accessed: 2025-12-29.
“Web-artifact from claude.ai,” https://claude.ai/public/artifacts/0ecdfb83-807b-4481-8456-8605d48a356c, accessed: 2025-12-06.
J. Howarth, “Number of parameters in gpt-4 (latest data),” https://explodingtopics.com/blog/gpt-parameters, 2025, last updated June 17, 2025; Accessed: 2025-12-06.