
Importance of Precise and accurate LLMs !
Motivation: In the financial domain, it is important to have highly precise and accurate responses from an LLM otherwise the impact can be catastrophic for users - Imagine how errors here could lead to not having enough to save for retirement, pay employees or owing taxes !
Problem Statement: General purpose Transformer models lack the granular domain expertise necessary for sophisticated financial insight generation. This project evaluates the impact of domain-specific parameter tuning on a base LLM architecture. By conducting a comparative performance analysis against the baseline, this study seeks to characterize the extent to which specialized fine-tuning improves semantic accuracy and reasoning within the financial services vertical.
Objectives: We seek to understand how effectively we can train an LLM on a single GPU to provide precise and accurate answers to questions related to company financial data.
Scope: Conduct training and ablation studies on a baseline LLM model and compare the performance versus the baseline. Identify a clear evaluation metric that determines an LLM's response is precise and accurate enough for a labeled professional response.
Technical Stack: PyTorch, Hugging Face Transformers, PEFT / LoRA, Hugging Face Datasets, Sentence Transformers
Phase 1 - LoRA Architecture
Goal: Determine the optimal capacity for domain-specific weight updates.
Action: Fix Learning Rate and Batch Size; sweep through LoRA Rank, Alpha, Dropout Rate
Evaluation: Identify the champion Adapter that maximizes financial reasoning without overfitting.
Phase 2 - Hyperparameter Tuning
Goal: Refine the training process to achieve peak accuracy.
Action: Lock the champion Adapter from Phase 1; vary Learning Rate and Batch Size(GradientAccumulation steps).
Evaluation: Map the impact of gradient density and step size on final model performance.
Experiment Design
Used meta-llama/Llama-3.2-3B-Instruct as the base model for all experiments and training. This is a smaller parameter model that has high-efficiency.
Success Metrics:
Semantic similarity - Used an embedding model, sentence-transformers/all-MiniLM-L6-v2, with cosine similarity.
Accuracy – Used a 90% semantic similarity threshold to assess accuracy versus the label.
Prompt: All models used zero-shot prompting.
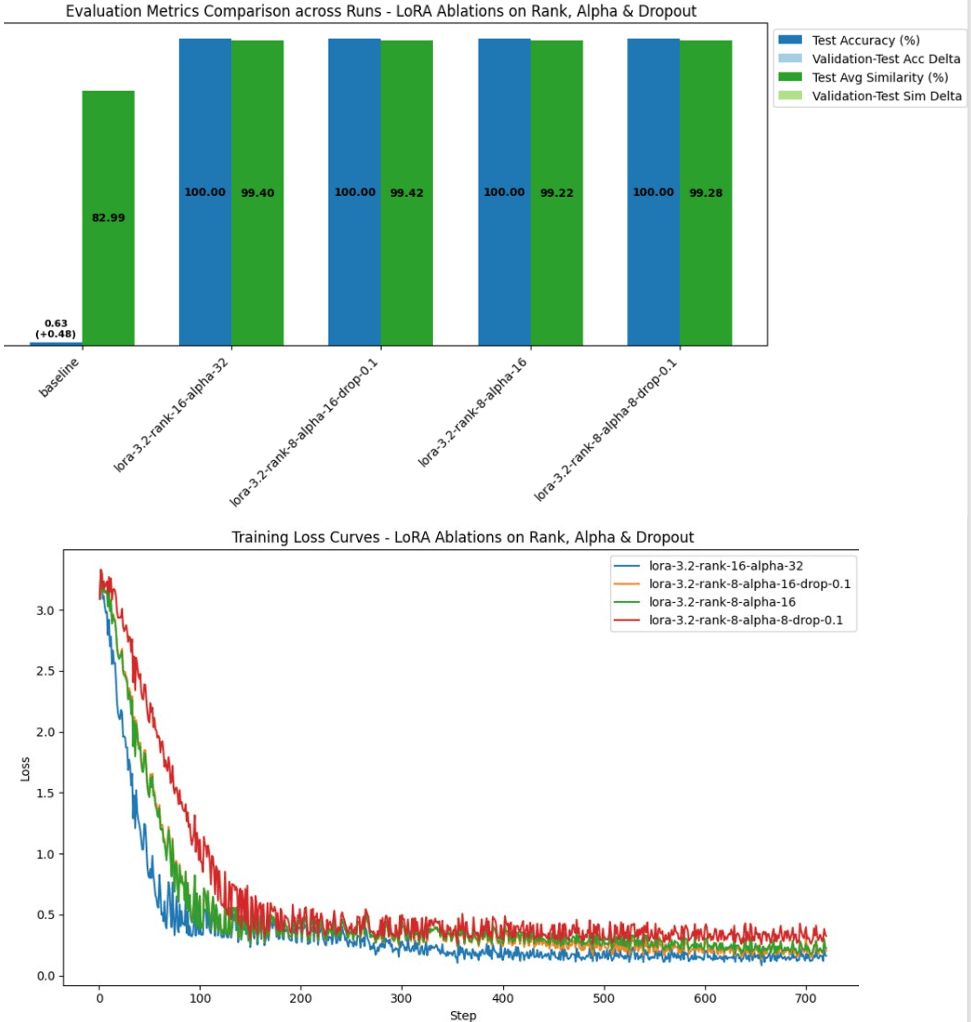
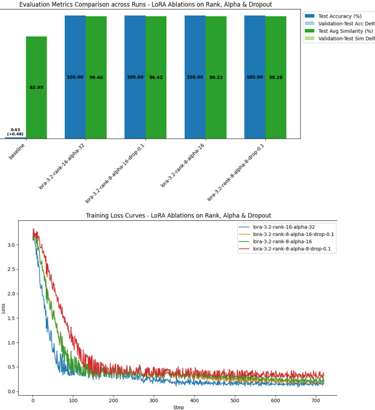
Phase 1:
LoRA Adapter Architecture
Varied values for Rank, Alpha andDropout rate on a subset ofexamples and conducted mini-training runs.
The following 2 configuration hadthe lowest loss:
Rank 16, Alpha 32, Dropout0.05
Rank 8, Alpha 15, Dropout 0.1
Overall, 2 above was the winner withthe highest similarity to the labele
Phase 2: Full Training Dynamics
Conducted full training usingPhase 1 LoRA architecture
Ablations include:
Gradient accumulationof 30 and 10.
Experimented with aStep Decay functioninstead of linear.
Gradient accumulation of 10with a 70% 3-step decayperformed the best
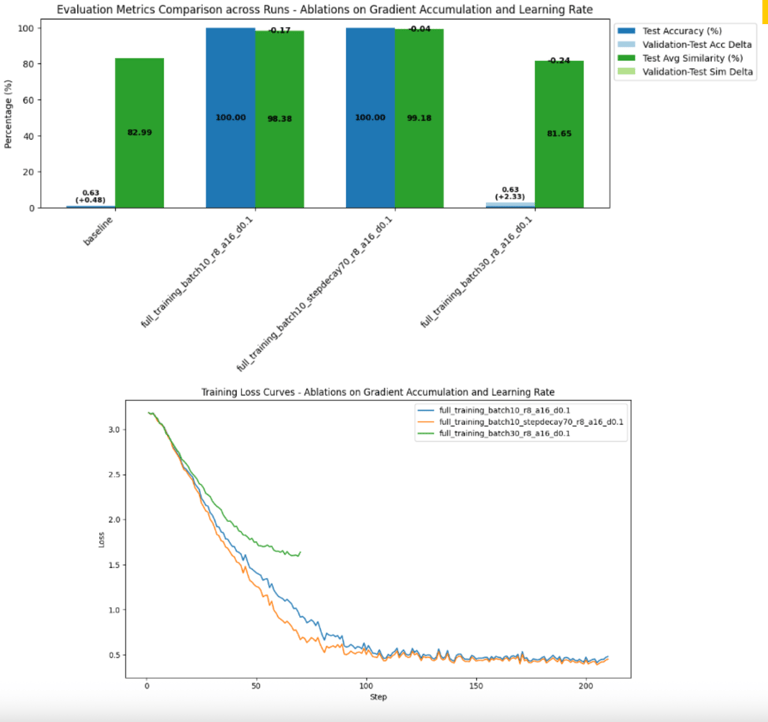
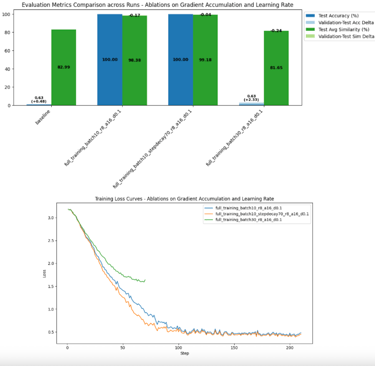
Conclusions
Final Results: Achieved >99% semantic similarity and 100% accuracy on both test and validation sets. Baseline was 83% semantic similarity and 0.01% accuracy on test and validation sets.
PEFT Efficacy: Validated that LoRA-based tuning effectively bridges the domain gap in financialreasoning, delivering specialized expertise with minimal computational and VRAM overhead.
Superior Performance: Achieved >99% semantic similarity and 100% accuracy on test andvalidation sets, demonstrating a significant performance delta over zero-shot baselines for high-stakesfinancial insight.
Optimal Training Dynamics: Determined through ablation studies that step-decay learning rates andmoderate gradient accumulation (10) are the primary drivers for model convergence and precision.
Scalable Deployment: Proved that small-parameter models, when surgically tuned, provide a cost-effective and high-throughput alternative to massive LLMs for enterprise asset managementapplications.
Limitations of Study: The dataset focusses on a subset of real-world financial data parameters toassess company performance and opportunities. While the dataset does vary the values of saidparameters within acceptable ranges as well as vary the available parameters on a given example, itis not necessarily comprehensive of all real-world cases.
References
N. Houlsby et al., “Parameter-Efficient Transfer Learning for NLP,” in Proc. 36th Int. Conf. Machine Learning (ICML), 2019, pp. 2790–2799
B. Lester, R. Al-Rfou, and N. Constant, “The Power of Scale for Parameter-Efficient Prompt Tuning,” in Proc. 2021 Conf. Empirical Methods in Natural Language Processing (EMNLP), 2021, pp. 3045–3059.
E. Ben Zaken, S. Goldberg, and Y. Ravfogel, “BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language Models,” in Proc. 60th Annu. Meeting Assoc. Computational Linguistics (ACL), 2022, pp. 1–9.
E. J. Hu et al., “LoRA: Low-Rank Adaptation of Large Language Models,” in Proc. Int. Conf. Learning Representations (ICLR), 2022.